2023. 1. 9. 15:40ㆍDataBase/DB 이론
[SQL] WHERE / HAVING
원하는 데이터의 조건에 맞춰서 해당 데이터를 꺼내올 때 사용하는 것이 바로 SQL이다. 이때 SQL에서 조건문은 두 가지가 존재한다. 바로 Where과 Having이다. 수업을 듣고 찾아오면서 해당 내용에 대해 간략하게 정리해보려고 한다.
WHERE
SELECT 열_이름 FROM 테이블_이름 WHERE 조건식;
먼저 WHERE의 문법의 방식이다. 해당 문법은 데이터를 들고 오는 과정에서 필터링을 하기 위해 사용이 된다.

해당 테이블은 제공이 된 buy라는 기본 테이블이며 쿼리로는 select * from buy로 테이블 내의 모든 데이터를 조회한 것이다. 그럼 만약 내가 price가 30인 제품만 가져오려면 어떤 방식을 취해야 할까? 이때 사용하는 것이 바로 where 절이다.
이 where 절에 price = 30을, 쿼리로는 where price = 30을 추가로 입력시켜주면 원하는 바와 같이 price가 30인 값만 등장하게 된다.
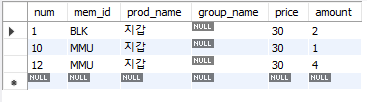
select * from buy where price = 30
해당 where 절에는 다양한 연산자를 사용할 수 있다.
- 관계연산자
- > < >= <= =
- 논리 연산자
- AND
- OR
- Like - 문자열의 일부 글자를 검색할때 사용
- % : 무엇이든 허용
- _ : 한글자 매치
- In - 문자로 표현이 되는 조건식을 조합할 때 편함
- select * from buy where price in(30,80)

해당 연산자를 통해 좀 더 다양한 범위의 조건절을 입력하여 필터링의 조건을 강화시킬 수도 있다. 혹은 between의 사용으로 조건문을 범위로 사용할 수 있다.

select * from buy where price = 30 or price = 50
- 가격이 30 || 50 인 제품의 출력
select * from buy where price between 30 and 50
-가격의 범위가 30-50인 제품 출력
HAVING
HAVING의 경우 먼저 집계함수에 대해 알아야 한다. where 절에서 집계함수를 사용하지 못하기에 해당 Having을 사용하게 됐다. 먼저 집계 함수의 경우 종류는 다음과 같다.
| 함수명 | 설명 |
| SUM() | 합계 |
| AVG() | 평균 |
| MIN() | 최소값 |
| MAX() | 최대값 |
| COUNT() | 행의 개수 |
| COUNT(DISTINCT) | 중복제거한 행의 개수 |

위의 이미지는 실제 워크밴치에서 WHERE로 조회했을 경우 콘솔에 나타나는 화면이다.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);
이때 집계함수를 사용하려면 조건문인 Having을 사용하면 된다. 해당 코드는 기본적인 HAVING의 틀이다.

실제로 WHERE에서는 해당 집계 함수를 사용할 수 없었고, HAVING에서는 집계함수의 사용이 가능했다.
참고
SQL WHERE Clause
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
SQL HAVING Clause
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
'DataBase > DB 이론' 카테고리의 다른 글
| [DataBase] CLOB / BLOB (0) | 2023.07.10 |
|---|---|
| [DataBase] RDB와 객체 지향적 특징의 차이 (0) | 2023.07.10 |
| [SQL] 테이블 별칭(ALIAS) (0) | 2022.05.24 |